大模型投机解码(三):Multi-token Prediction — 让模型自己当 Draft
论文: Better & Faster Large Language Models via Multi-token Prediction
作者: Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve
机构: Meta / FAIR
发表: 2024 | arXiv:2404.19737
一句话总结: 训练时让模型同时预测未来 n 个 token,推理时用额外的预测头充当 draft model,实现”自己给自己投机解码”,无需额外小模型即可获得 3X 加速。
一、回顾:经典投机解码的痛点
Speculative Decoding 的核心框架:用小模型猜、大模型验。这个框架优雅且精确等价,但在实际落地时有一个挥之不去的问题——你需要一个额外的 draft model。
1 | 经典 Speculative Decoding 的部署代价: |
有没有可能,让大模型自己就能猜多个 token,然后自己验证自己?
Meta/FAIR 的这篇论文给出了一个巧妙的方案:在训练阶段让模型学会同时预测多个未来 token。推理时,这些额外的预测头天然就是现成的 “draft”——不需要额外模型,不占额外显存,不存在选型问题。
二、核心思想:同时预测多个未来 token
标准的语言模型训练用 next-token prediction:在每个位置
Multi-token Prediction (MTP) 把这个目标推广为:在每个位置同时预测接下来的
注意:这里每个未来 token 的预测都只依赖已观察到的上文
1 | 标准训练(n=1): MTP 训练(n=4): |
三、架构设计
共享主干 + 独立预测头
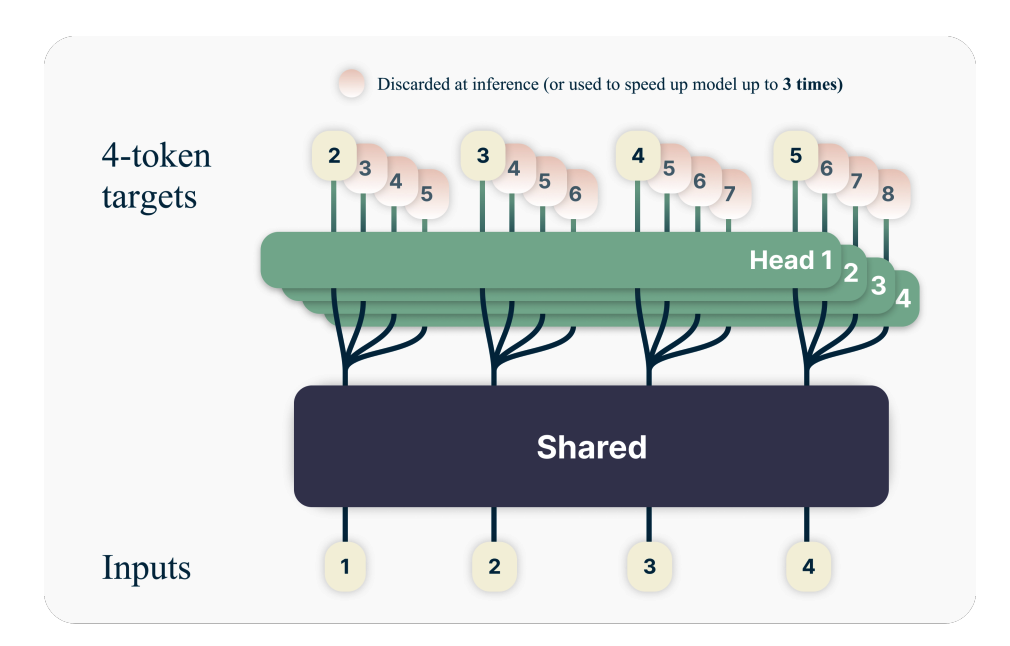
如图所示,模型由三部分组成:
- 共享 Transformer 主干(图中深色 Shared):把输入序列编码为隐藏表示
,与标准 Transformer 完全一样 - 主预测头 Head 1(图中绿色):接在主干之上,预测下一个 token——就是标准语言模型的输出头
- 额外预测头 Head 2 ~ Head
:每个头是一个独立的 Transformer 层,分别预测第 2 ~ 第 个未来 token。推理时可丢弃,或用于 self-speculative decoding 加速(最高 3X)
所有预测头共享同一个 unembedding 矩阵
Memory-Efficient 训练
1 | z = model.shared(x) # 共享主干前向 |
对每个头顺序执行前向 + 反向,算完一个头就释放其 logit 和梯度,再算下一个。这样峰值显存从
| 模型 | n=1 | n=2 | n=4 |
|---|---|---|---|
| 0.3B | 1.00 | 1.07 | 1.22 |
| 1.3B | 1.00 | 1.04 | 1.12 |
| 6.7B | 1.00 | 1.02 | 1.07 |
| 13B | 1.00 | 1.04 | 1.09 |
13B 模型用 4-token prediction 训练,时间只增加 9%。模型越大,相对开销越小。
公平对比:参数量一致
为了保证公平,每增加
四、Self-Speculative Decoding:自己给自己当 Draft
这是本文的核心。回顾经典投机解码的流程:
1 | 经典 SD: 小模型猜 γ 个 → 大模型验证 → 接受/拒绝 |
在 MTP 框架下,额外的预测头(Head 2, 3, 4)天然充当了 draft model 的角色。
完整流程
假设用 4-token prediction 模型(
Step 1:一次 forward pass,出 4 个预测。
输入当前 prefix,共享主干计算一次,然后 4 个头各自给出预测:
1 | Head 1 → token A(next-token,这是"标准答案"的分布) |
Step 2:把猜测序列喂回去验证。
把 Head 2/3/4 的猜测 [B, C, D] 拼到 prefix 后面,再做一次 forward pass。这次 Head 1 会在每个位置给出”标准答案”的分布,用于验证 [B, C, D] 是否正确。
1 | prefix + [A] → Head 1 验证 B |
Step 3:从左到右验证,拒绝第一个不一致的。
验证逻辑和经典投机解码完全一样(参见上一篇的 speculative sampling)。区别仅在于 draft 分布来自额外预测头,而非独立小模型。
Step 4:输出接受的 token + 修正采样。
1 | 最好情况:A, B, C, D 全部接受 + 额外采样 1 个 = 5 个 token |
与经典 SD 的关键区别
1 | ┌────────────────────┬───────────────────┬──────────────────────┐ |
注意论文实现的是 greedy self-speculative decoding(blockwise parallel decoding),验证逻辑比经典 SD 更简单:额外头的预测要么和 Head 1 的 argmax 一致就接受,不一致就拒绝,不涉及概率比的随机接受。
为什么额外头是好的 Draft?
MTP 训练的额外头和主头共享同一个 trunk 表示,它们看到的是完全相同的隐藏特征。这比独立小模型有天然优势:
- 表示对齐:额外头从主干的最终表示出发,本身就包含了大模型的全部理解
- 训练一致:额外头和主头在相同数据上联合训练,分布天然接近
- 零额外 forward:猜测阶段只需要过额外头(单层 Transformer),不需要再跑一次完整模型
论文特别指出:MTP 预训练比单纯在已有模型上微调额外头效果好得多——从头联合训练让主干的表示本身就变得对多步预测更友好。
五、实验:推理加速效果
论文用 7B 参数的 4-token prediction 模型,在代码和自然语言上测试 self-speculative decoding 的加速效果。
主要加速数据
| 域 | 使用头数 |
相对加速 | 每次 forward 产出 token 数 |
|---|---|---|---|
| 代码 | 1 | 1.00x | 1.00 |
| 2 | 1.85x | 1.94 | |
| 3 | 2.54x | 2.78 | |
| 4 | 3.05x | 3.50 | |
| Wikipedia | 1 | 1.00x | 1.00 |
| 2 | 1.79x | 1.88 | |
| 3 | 2.35x | 2.57 | |
| 4 | 2.74x | 3.12 | |
| Books | 1 | 1.00x | 1.00 |
| 2 | 1.77x | 1.87 | |
| 3 | 2.32x | 2.56 | |
| 4 | 2.57x | 2.67 |
代码场景加速最显著(3.05x),因为代码中重复模式多、下一个 token 更可预测,额外头的猜测准确率更高。
关键观察
加速在所有 batch size 下都成立。 经典 SD 在大 batch size 下加速会衰减(因为 draft model 的额外计算在 compute bound 场景下变得不划算)。而 MTP 的额外头非常轻量,加速比在 batch size 1 到 40 之间几乎恒定。
1 | 经典 SD:batch size ↑ → 加速 ↓(compute bound 下 draft 开销凸显) |
这是 self-speculative decoding 相对经典 SD 的一个重要实用优势。
Byte-level 模型:加速更惊人
论文还在 byte-level tokenizer 上做了实验(直接预测字节而非 subword token),8-byte prediction 模型:
| 使用头数 |
相对加速 |
|---|---|
| 2 | 1.94x |
| 4 | 3.67x |
| 8 | 6.39x |
Byte-level 模型的序列更长(一个 subword 对应多个字节),但 self-speculative decoding 可以完全弥补这个代价,甚至让 byte-level 模型的推理速度接近 token-level 模型。
六、附带收益:MTP 还让模型更强
虽然本文侧重推理加速,但值得一提的是 MTP 训练不仅快,还让模型本身变得更好。这不是推理 trick,而是训练范式的升级。
模型越大,MTP 收益越大
在 MBPP 代码生成 benchmark 上,MTP 相对 baseline 的提升随模型增大而增大:
| 模型 | Baseline pass@1 | 4-token MTP pass@1 | 提升 |
|---|---|---|---|
| 0.3B | 1.8 | 1.0 | -0.8 |
| 1.3B | 6.8 | 7.4 | +0.6 |
| 3B | 11.1 | 12.7 | +1.6 |
| 6.7B | 23.9 | 26.0 | +2.1 |
| 13B | 26.0 | 30.5 | +4.5 |
小模型(< 1B)反而略有退化,但 3B 以上就稳定超过 baseline,13B 时 pass@1 提升 4.5 个百分点。论文认为这是 MTP 被长期忽视的原因之一:之前的研究多在小模型上实验,没看到 scaling 后的收益。
为什么 MTP 能提升模型质量?
论文给出了一个直觉解释:MTP 让模型更关注”关键决策点”。
1 | Ground truth: 1 → 2 → 3 → 4 → 5 → A → B |
从信息论角度看,2-token prediction 让模型对相邻 token 之间互信息
七、从并行到串行:DeepSeek-V3 的演进
Meta 的 MTP 设计是并行多头:4 个独立 head 各管一个位置,互不依赖。这在训练时很自然——4 个 head 可以并行算 loss;但在推理时有一个致命限制:无法做树形展开。
1 | 并行 MTP(Meta): |
DeepSeek-V3(2024.12)把这个设计改成了串行单 module:只用 1 个 MTP module,每步接收上一步的输出作为输入,自回归循环任意多步。
1 | 串行 MTP(DeepSeek-V3): |
这个改动的核心动机是投机解码:串行设计让 MTP module 可以像 EAGLE 的 Autoregression Head 一样,在每步 top-k 采样产生多个分支,构造树状草稿。并行设计做不到这一点。
1 | 并行多头: 4 个 head → 只能猜固定 4 步 → 链式草稿 |
Qwen3.5 也跟进了这个设计(mtp\_num\_hidden\_layers: 1),串行单 MTP module 正在成为业界惯例。原因很简单:对于推理加速来说,1 个能自回归循环的 module 严格优于 N 个各管一个位置的 head——前者能造树,后者不能。
值得注意的是,这使得 MTP 和 EAGLE 在架构上趋于收敛:
| 维度 | EAGLE | 串行 MTP |
|---|---|---|
| Draft module | 额外训的 1 层 Decoder | 预训练自带的 1 个 MTP Module |
| 自回归循环 | 是 | 是 |
| 树形展开 | 是 | 是 |
| 动态剪枝 | 是(EAGLE-2) | 可复用 EAGLE-2 策略 |
| 与 target 的关系 | 事后训练,蒸馏 | 联合预训练,原生对齐 |
两者的区别已经不在推理架构上,而在 draft module 怎么来的——EAGLE 是后训的,MTP 是预训练内置的。验证侧完全通用。
八、对比总结
三种投机解码方案对比
| 维度 | 经典 SD | 并行 MTP(Meta) | 串行 MTP(DeepSeek-V3) |
|---|---|---|---|
| 提出时间 | 2022 | 2024.04 | 2024.12 |
| 核心思路 | 小模型猜 + 大模型验 | 多个并行 head 猜 + 主头验 | 单 module 自回归猜 + 主头验 |
| 需要 draft model | 是 | 否 | 否 |
| 额外显存 | 需加载 draft model | 几个预测头,可忽略 | 1 个 module,可忽略 |
| 训练要求 | 无(即插即用) | 需要 MTP 预训练 | 需要 MTP 预训练 |
| 树形展开 | 可以 | 不可以(深度=head 数) | 可以(深度不受限) |
| 加速倍数 | 2-3X | 2.5-3X | 潜力更高(可接树形验证) |
| 模型质量影响 | 无 | 正面 | 正面 |
三种方案的演进脉络很清晰:经典 SD 是推理时方案,对任何已有模型即插即用;Meta 的并行 MTP 是训练时方案,一石二鸟但推理受限于固定深度;DeepSeek-V3 的串行 MTP 把两者的优势合并——预训练内置 draft 能力,推理时又能像 EAGLE 一样做树形展开。