NanoSpec:用上下文最小词表给投机解码再提速
论文: NanoSpec: Accelerating Speculative Decoding using Minimalist In-Context Vocabularies
作者: Zhiyang Chen, Daliang Xu, Yinyuan Zhang, Chenghua Wang, Mengwei Xu, Yun Ma
机构: 北京大学 / 北京邮电大学
发表: ICML 2026 | arXiv:2605.26444
一句话总结: 每步根据上下文动态构造一个 <3k 的 draft 词表,与 EAGLE-2/3 搭配时 draft 时间约减半,端到端 1.17–1.29×。
一、问题:被忽视的 LM head 瓶颈
经典 Speculative Decoding(详见这篇)依赖一个简单的等式:只要 draft 足够快,就能用大模型一次并行验证一串猜测。EAGLE、Medusa 把 draft 砍到只剩一两层 Transformer 之后,draft backbone 已经非常瘦,但加速比却卡住了。
瓶颈跑哪儿去了?藏在 LM head 里。
现代 LLM 词表越做越大:Llama-3 是 128k,Qwen-2.5 是 152k。draft model 每生成一个候选 token,都要做一次
1 | Llama-3.1-8B 上 EAGLE-2 单步 draft 耗时分解: |
LM head 的算并不复杂,复杂的是它的规模。一个直接的想法是:既然 draft 只是猜,干嘛非得用 128k 的全词表?砍掉不就好了?
1 | 反正最终 token 都要被 target model 验证, |
于是出现了一系列”draft 词表剪枝”的方法。但它们都没把这条路走到头。
二、为什么静态词表走不远
主流方案分两类:
- 静态高频词表:FR-Spec、VocabTrim 直接按语料频率取 top-K 当作 draft 的词表。简单,免训练,但跟当前上下文完全无关。
- 路由到预聚类簇:DynaSpec、CORAL 把全词表离线聚成几百个簇,再训一个小 MLP router 在每一步选若干个簇。能感知一点上下文,但仍然是粗粒度,而且要训练。
两类方法都被同一个困境绑住了:词表越小,draft 算得越快;但词表一旦砍小,long-tail token 漏掉,acceptance rate 暴跌。
论文用一个”oracle vs actual”的实验把这个困境量化得很直白。定义:
oracle 假设缩小词表完全不影响 acceptance length,纯粹给 LM head 提速;actual 则是用 FR-Spec 跑出来的真实速度。Llama-3.1-8B 上,两条曲线的差距很直观:
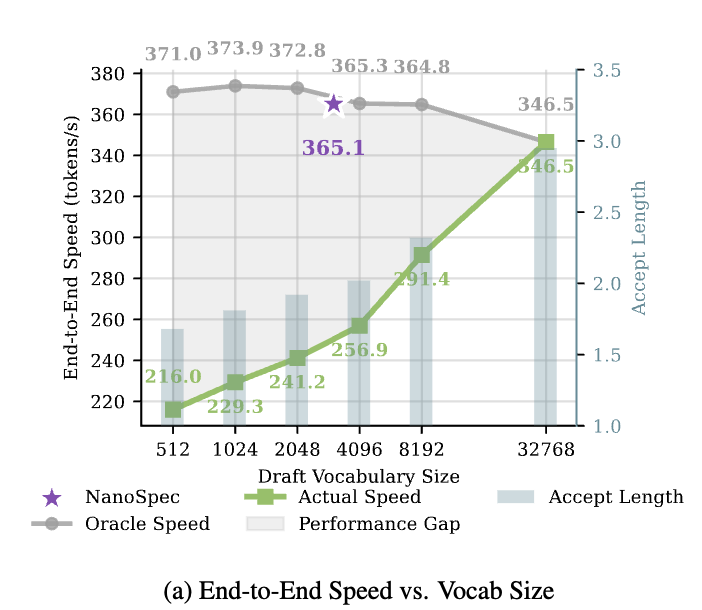
理论上从 32k 缩到 2k–4k 附近仍该继续受益;但实际 16k 以下就开始跳水,到 2k 只剩 241.2 tok/s。所有的”untapped potential”都被 acceptance rate 的崩塌吃掉了。
再看 ground truth coverage——目标 token 落在 draft 词表里的概率。静态方法(FR-Spec)在 Conv./Summ./Math/Code/MT./QA/RAG 七个任务上要堆到 16k–32k 才能做到 >85% 的覆盖率;而 NanoSpec 用 <3k 的动态词表就拿到了 73%–97% 的覆盖率。
结论很清楚:问题不在”词表能不能小”,而在”小词表是不是认得当前这一句话”。
三、关键洞察:generation 的 temporal locality
为什么 3k 够?因为 LLM 生成本身就具有强 temporal locality。
1 | "The old wooden ship had ___" |
这些 token 的并集,其实不到几千个。FR-Spec 漏掉的 long-tail(hull、barnacle、weathered),并不是真正意义上的 long-tail,它们只是”在这一句话里高频”的局部高频词——只要词表跟着上下文走,就能把它们抓回来。
NanoSpec 的全部算法设计都建立在这个观察上:最优 draft 词表是一个随 step 变化的滑动子集,由最近的上下文 token 与最近被高分提名的 token 共同组成。
四、算法:上下文驱动的动态词表
NanoSpec 把动态词表形式化成一个不断追加的”候选流”
4.1 Prefill 阶段:候选流初始化
给定 prompt
4.2 Decoding 阶段:每步追加新候选
每一个 decoding step
:本轮 draft tree 出现过的全部 unique token id(不论是否被接受)。 :target 在该步给出的 top- 候选。
把它们追加到流尾:
draft tree 的候选承载”draft 自己想到了什么”,verify top-K 承载”target 真正在意什么”——前者是探索,后者是修正。论文消融显示两者都不可少(只用前者 351.4 tok/s,只用 prefill 313.3 tok/s,合用到 364.1 tok/s)。
4.3 滑动窗口取活跃词表
为了限制内存与计算,NanoSpec 在流尾取最近
这是一个隐式的 LRU 淘汰:太久没出现过的 token 自然就被挤出窗口。论文里
4.4 一个 walkthrough
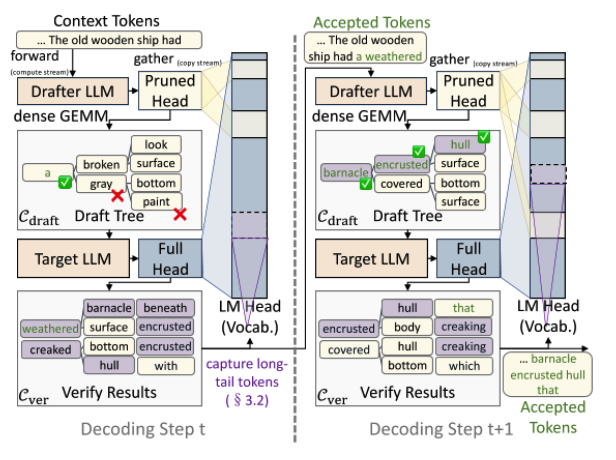
借用论文图 2 的 toy example。上下文是 ... The old wooden ship had,用 NanoSpec:
1 | S 里此刻包含: |
下一步 draft 用 weathered hull encrusted with barnacle ... 这种与上下文高度匹配的延续;而 FR-Spec 的静态高频表里 hull/barnacle/encrusted 多半根本不在,只能退中求其次给出 broken surface 之类的通用替代。
五、系统协同
- 异步 gather:预分配 GPU buffer,每步把
行 pack 成连续矩阵,LM head 走 dense GEMM。 - 双 CUDA stream:copy stream 的 gather 与 compute stream 的 draft backbone 并行,gather 延迟被算开销吸收。
- GPU-resident bitmap:lock-free CUDA kernel 在 VRAM 维护
,避免 host↔device 同步。额外 VRAM 约 24 MB。
这三件都是绑定 NVIDIA 的工程优化。论文 ablation(Table 5)显示,去掉双流的朴素 indexed GEMM 仍能跑到 364.1 tok/s,对比完整 392.7 只差 7%——主要收益在算法侧(§4),系统层是锦上添花。在 UMA 架构(如 Apple Silicon)或非 CUDA 后端上,这部分要重新设计,但 §4 的算法可以直接复用。
LM head 速度账(Table 4):full vocab 2.330 ms → NanoSpec 0.237 ms;单步 draft 3.735 → 1.640 ms。
六、实验结果
Llama-3.1-8B / Llama-3.2-1B / Qwen-2-7B,SpecBench + HumanEval,单卡 H20。几个关键数字:
- 端到端:搭 EAGLE-2 时,8B 上比 full-vocab 快 1.17×、比 FR-Spec 快 1.06×;1B 上对 FR-Spec 拉到 1.16×。换 EAGLE-3 趋势一致,8B 1.19×、1B 1.28×。
- draft 耗时:比 EAGLE-2 少 51.6%,比已做静态剪枝的 FR-Spec 还少 20.3%——主要省在 LM head(2.33 ms → 0.24 ms)。
- acceptance length:与 full-vocab 基本持平,部分任务还略高——剔除无关 token 后 softmax 质量更集中。
- 模型规模相关性:1B 的提升明显大于 8B,因为越小的模型 LM head 占比越高。这也是 NanoSpec 真正的甜点区。
七、特性与思考
适用边界。 受 Amdahl’s Law 限制,target 扩到 70B+ 后 verify 主导端到端,draft 再快也救不了多少。NanoSpec 的甜点是 1B–8B + 大词表,尤其 1B 这种 backbone 已经压不动、LM head 才是瓶颈的小模型——也是边端、移动场景最关心的一档。
training-free,正交于现有栈。 只动 draft 的 LM head 路径,不训 router、不改 target、不动 KV cache、不改 scheduler;与 PagedAttention / EAGLE-2/3 这类 tree-based SD 天然兼容。超参就
八、小结
Speculative Decoding 解决了自回归串行,EAGLE 把 draft backbone 压到极致,NanoSpec 则瞄向再下一层——随词表规模膨胀的 draft LM head。
做法不复杂:基于”下一个 token 多半在最近上下文里”这个观察,每步动态取一个 <3k 子词表做 LM head;CUDA 上再加双流 + GPU-resident bitmap 把稀疏访问开销吃掉。target 与精确等价性都没动。
1 | Speculative Decoding ─→ 解决"串行" |
需要注意:论文报告的端到端数字依赖 §5 那套 CUDA 工程,跨平台移植时主要可复用价值在 §4 的算法本身。