大模型量化系列(四):AWQ — 用 Activation 找到关键 Weight
论文: AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration
作者: Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang 等
发表: MLSys 2024 Best Paper | arXiv:2306.00978
一句话总结: AWQ 用 activation 找到关键 weight channel,再通过等价缩放降低它们的相对量化误差,在不做重构、不引入混合精度路径的情况下实现高质量 W4A16 部署。
一、GPTQ 之后,AWQ 在问什么问题
上一篇 GPTQ 解决的是 weight-only 低比特量化里的一个核心问题:
如果只把 weight 压到 3/4 bit,怎样避免简单取整把 layer output 搞坏?
GPTQ 的答案是二阶补偿:用 calibration activation 构造 Hessian 信息,量化后再调整剩余 weight 来补偿输出误差。它的强项是准确,代价是需要 layer-wise reconstruction,可能更依赖校准数据分布。
AWQ 换了一个角度:
能不能先判断哪些 weight 更重要,然后在量化之前就保护它们?
它最后没有真的保留 FP16 weight,而是用更硬件友好的等价缩放达到类似保护效果。
二、核心观察:不是所有 Weight 都一样重要
AWQ 的第一个观察很直接:LLM 的 weight 并不等价。只保护大约 0.1% 到 1% 的 salient weights,低比特量化的 perplexity 就能明显改善。
论文里的实验很典型:OPT 做 INT3 group-wise quantization 时,RTN 会明显退化;如果把少量重要 weight channel 保持 FP16,效果会接近原模型。
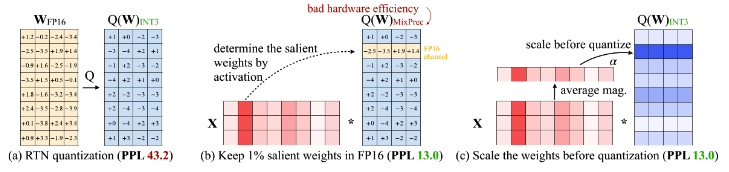
关键问题是:这些重要 weight 怎么找?
直接看 weight magnitude 或 L2 norm 并不好用。真正有效的信号来自 activation:如果某个输入 channel 的 activation 幅度长期更大,对应的 weight channel 往往更重要。
换句话说,weight 的重要性不只由 weight 自己决定,而是由它和真实 activation 的交互决定。
这一点和前几篇文章可以连起来看:
1 | LLM.int8(): activation outlier 会破坏朴素 INT8 |
AWQ 的名字 Activation-aware Weight Quantization,核心就在这里:量化的是 weight,但判断重要性要看 activation。
三、为什么不直接保留 1% FP16 Weight
既然保护 1% salient weights 就有效,最直接的方案是:
1 | 普通 weight -> INT4 / INT3 |
这在精度上有效,但在系统上麻烦。
weight-only 量化不只是让模型文件变小,还要让推理路径简单。理想状态是所有 weight 都按统一 INT4 layout 存储,kernel 可以连续访存、解包、反量化和计算。
如果少数 weight 还要保留 FP16,就会引入混合格式:
1 | 大部分 INT4 weight + 少量 FP16 weight |
这会破坏连续的低比特布局。kernel 需要区分 FP16 和 INT4 位置,计算路径也可能被拆开。对 GPU、移动 GPU、ARM CPU 来说,这些额外访存和控制流很容易吃掉量化收益。
所以 AWQ 的目标变成:
不真的保留 FP16 salient weights,但让它们在量化时受到类似保护。
这就是 activation-aware scaling 的动机。
四、核心方法:用缩放降低相对量化误差
先看一组 weight
其中:
现在考虑一个线性计算:
把重要 weight channel 放大
但量化之后,误差会变。AWQ 使用的是:
把量化函数展开:
如果
这就是 AWQ 最关键的技巧:
1 | 不是把关键 weight 保留成 FP16, |
但
所以 AWQ 的问题不是“放不放大”,而是“放大多少”。
五、AWQ 怎样搜索 Scaling Factor
AWQ 对每个线性层搜索 per-channel scaling factor,让量化后的输出尽量接近原始输出:
其中:
这里
形式上它和 SmoothQuant 很像:
但目的不同。SmoothQuant 是让 activation 更容易做 INT8;AWQ 是让重要 weight 在 INT3/INT4 下误差更小。
AWQ 不直接对
其中
这个设计很克制:不做复杂重构,不用梯度更新,只统计 activation scale,再搜索合适的缩放强度。论文还配合 weight clipping 降低量化 MSE。
流程可以概括成四步:
- 收集每层输入 activation 的 channel-wise 平均幅度。
- 构造
的候选缩放。 - 对
做 INT3/INT4 group-wise quantization。 - 选择让 layer output 重构误差最小的
,并把 融合到前一层或相邻算子中。
它不是 GPTQ 那种“量化后补偿”,而是“量化前保护”。
六、为什么 AWQ 泛化性更好
AWQ 强调自己不依赖 backpropagation,也不做 GPTQ 那种 weight reconstruction。它主要使用 activation 的统计量,尤其是 channel-wise average magnitude。
这带来两个好处。
第一,校准数据需求更小。AWQ 只需要稳定估计 activation scale,不需要大量样本来支撑重构过程。
第二,对校准分布更不敏感。论文用 PubMed 和 Enron 做交叉实验:校准集和评估集分布不一致时,GPTQ 的 perplexity 退化更明显,而 AWQ 更稳。
这对通用大模型很重要。LLM 部署后会面对聊天、代码、数学、视觉语言等多种场景,量化方法如果过度拟合校准集,反而会损伤泛化。AWQ 在 instruction-tuned models、coding/math benchmarks 和 VLM 上的实验,就是为了证明这一点。
七、TinyChat:从 W4A16 到真实加速
AWQ 论文还配套实现了 TinyChat,用来说明 W4A16 不只是模型文件变小,也能转化成真实推理加速。
这里的关键背景是:on-device LLM 的 decode 阶段通常受内存带宽限制,每生成一个 token 都要读取大量权重。把 FP16 weight 压到 INT4,可以显著减少权重读取量;但系统还需要高效完成 INT4 解包、反量化和矩阵乘,否则收益会被 kernel 开销吃掉。
TinyChat 做的就是这部分工程落地。论文报告它相比 HuggingFace FP16 实现有 3 倍以上加速,并展示了 Jetson Orin、RTX 4070 laptop、Raspberry Pi 等设备上的部署结果。
八、AWQ 和 GPTQ 的关系
AWQ 经常和 GPTQ 一起出现,但思路不同。
GPTQ 的关键词是 reconstruction:用 Hessian inverse 做二阶补偿,让量化后的 weight 重构原始层输出。
AWQ 的关键词是 saliency:用 activation 判断哪些 weight channel 更重要,再通过缩放降低它们的相对量化误差。
可以这样理解:
1 | GPTQ:量化会造成误差,那就用剩余 weight 去补偿。 |
两者并不互斥。论文在 INT2 实验中显示,AWQ 可以和 GPTQ 结合:AWQ 先提供 activation-aware 保护,GPTQ 再做二阶补偿。
但从部署角度看,AWQ 更强调简单和硬件友好:不做复杂重构,不需要 reorder trick,也不引入 FP16/INT4 混合格式。
九、个人评价:AWQ 的价值在于找到了更好的重要性信号
AWQ 最值得记住的,不是“把 weight 放大再量化”,而是它重新定义了 weight-only 量化里的重要性判断:量化的是 weight,但真正有用的保护信号来自 activation。
它也让 AWQ 在整个量化系列里占了一个独特位置:
1 | LLM.int8():发现 activation outlier |
它不是 GPTQ 的简单替代品,而是把问题往前推了一步:不只问“量化误差怎么补”,还要问“哪些权重一开始就该被保护”。
当然,AWQ 主要解决 weight-only quantization,对 activation、KV cache 和完整 serving stack 的其他瓶颈并没有一并解决。但站在 2026 年看,它已经成为 4-bit LLM 部署里的重要路线,并证明了一件事:
量化一个模型时,最有价值的信息不一定在被量化的张量里,也可能藏在它所处理的 activation 里。